Judging LLM judgement
This is from my early days of consulting. I am excited about the start of a heavy industrial goods case. I book a room, grab some coffee, and churn through the annual report of a company. I proudly take the slides to the associate partner and present it to him. He takes a look at the slides. Then he looks at me and thinks for a bit. Perhaps he is thinking about the exact way to land the message. It is clear that I have not done a great job. Because the annual report painted a rosy picture of the company’s future earnings, and tried to hide its shortcomings. His thinking lands. Because I still remember his core message. “Always use analyst reports instead of the annual report to get an overview. The analysts would do their research and paint a more skeptical, a more real picture” - he said. What he really wanted to say was “Use their judgement, till you develop yours”. This was 2017. Almost a decade later, I am still thinking about judgement in this context of LLMs and AI.
I got a taste of judgement across LLMs when I was investigating the effects of chai on headaches. Gemini convinced me that my ginger chai was the elixir of life, while Claude told me clearly that this was all pop science BS. Some screenshots below:
 Gemini decided I was Walter White.
Gemini decided I was Walter White.
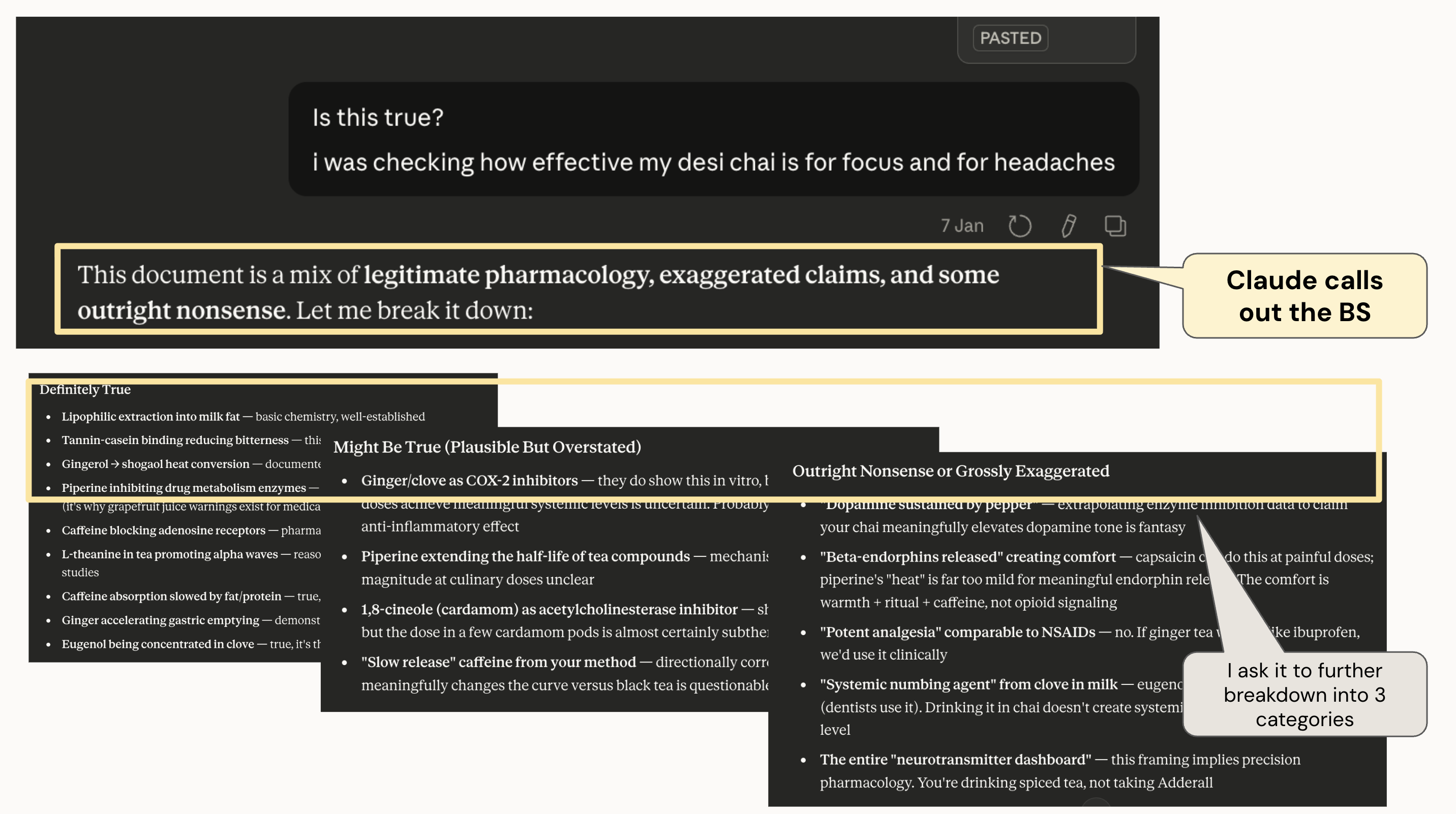 I then asked Claude the same question. Different experience.
I then asked Claude the same question. Different experience.
I wanted to assess this further. So, I pretended for a Sunday evening that I am part of a frontier research lab and performed a few evals. I asked Claude, Perplexity, Gemini and ChatGPT (Free version, because I stopped paying for it^) the same question, and then rated them (out of 10) on
- Research: How good was the research
- Judgement: How did it judge the info it researched
- Presentation: How crisply did it present the info?
The question was: Has Grammarly been able to weather the AI storm, and come out well positioned? Or has it been affected in a material way?
Short answer - yes. Even though AI hasn’t killed the company, it has pushed the company into the “growth via product acquisition” territory. Grammarly now owns Coda and Superhuman. I am sure these make the narrative of a “productivity suite” easier to sell to investors but it might take a LOT of work to get this one right. The customer segments and their jobs-to-be-done are different, the products are different, and the people behind the product are different too. It’s not surprising that only 20-30% of such consolidations in B2B SaaS are successful. The legendary Slack and Salesforce integration is yet to yield the returns people expected.
This is how the LLMs responded to the question:


From both examples, it is pretty clear that Claude does a better job at judging information. It is better at not accepting things at face value. I like its thoughtfulness, its judgment, and its wisdom. And, I am not alone in this. It’s not uncommon to hear new Claude converts (or Plebeians) say “Claude’s answers are generally better” or “I wish I had started using Claude sooner”.
In “The Intelligence Trap”, David Robson argues that wisdom is a better predictor of success than raw IQ. I think something similar is true here. Notwithstanding the rate limits, Claude seems like a wiser bot to deal with despite underperforming ChatGPT in some benchmarks (GDPVal). Standard LLM benchmarks (Humanity’s last exam, GDPval, SWE-bench verified etc.) all filter for the seemingly smart student. Not the wise one. Maybe they should.